![]()
 |
![]()
Decision trees are the most popular method for data analysis and classifier construction. With the dtree package I provided a set of command line programs written in C, with which decision and regression trees can be grown and pruned as well as executed on new data. However, these programs lacked a graphical user interface and, in particular, the possibility to visualize a learned decision or regression tree. This drawback is amended with this graphical user interface, which contains (at least) one tab for each program and also comprises a decision tree viewer. This page only describes the graphical user interface, though. The description of the viewer, which may also be obtained as a separate program, can be found here.
Enjoy,
Christian Borgelt
| back to the top |  |
![]()
To start the program from the jar file, type java -jar dtgui.jar or java -classpath dtgui.jar dtree.DTreeGUI, to start it from the compiled sources, type java dtree.DTreeGUI.
The dialog box contains seven tabs, four of which correspond to the command line programs dom (domain determination, contained in the table package) dti (decision tree induction), dtp (decision tree pruning) und dtx (decision tree execution, all three contained in the dtree package).
| back to the top | |
![]()
On the first tab the format of the data file can be specified:
(Note that this tab is not executable.)
It is assumed that a data file consists of several records, each of which contains several fields (but all records have the same number of fields). As their names indicate, record separators separate records and field separators separate fields within a record. Blanks are characters that are used only to fill fields, for example to achieve a certain width, so that fields of different records are aligned in a text editor. They are removed when the file is read for processing. Unknown value characters are used to identify unknown or missing values. A field containing only such characters is assumed to be unknown or missing.
By default it is assumed that the first record of the data file contains the names of fields. If this is not the case, the corresponding box should be unchecked, so that default names (field numbers, starting with 1) are generated.
The last field of each record of the data file may contain an occurrence counter. Checking the corresponding box tells the programs about this, so that the last field is not interpreted as a data value, but as a record weight. If no such explicit weight is present, each record is assigned a uniform weight of 1.
| back to the top | |
![]()
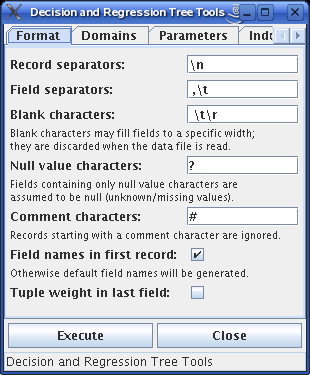
With the second tab attribute domains can be determined:
The decision tree induction program needs as input a description of the domains of the attributes. This tab serves the purpose to generate such a domain description from the data file, which is done when this it is in front and the "execute" button is pressed. The attribute types are determined automatically if the corresponding box is checked. This may fail: If a nominal attribute has numbers as values, which have no numeric meaning, the program will still assume that the attribute is numeric. To correct such things the generated domain file has to be edited. This can be done by pressing the Edit button, which opens a simple text editor.
This tab also lets you locate the underlying programs if they cannot be found through the "path" environment variable. If you place the programs into the same directory where you start this graphical user interface, locating the programs should not be necessary.
| back to the top | |
![]()
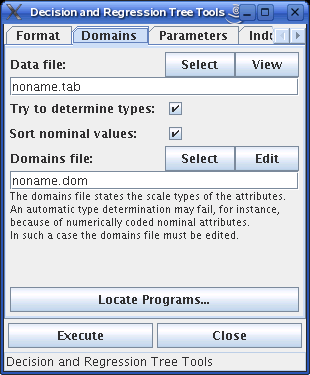
The third tab contains the parameters that influence the decision
tree induction:
(Note that this tab is not executable.)
The evaluation measure is used to choose the test attributes and the tests, and it may be weighted with the fraction of known values of the attribute. The upper measure is for decision trees, the lower for regression trees. Which of the two selected measure is used depends on the type of the target attribute.
For the evaluation measure a minimum value may be specified, which has to be exceeded for a split to be generated. Some measures can make use of specific parameters, the meaning of which are explained in the book Graphical Models - Methods for Data Analysis and Mining by Christian Borgelt and Rudolf Kruse, J. Wiley and Sons, Chichester, United Kingdom 2002. For standard applications these parameters may safely be ignored. Furthermore a maximum height of the tree to be grown can be set (with 0 meaning that there is no limit) as well as a minimum support, which has to be exceeded by at least two branches for a split to be generated. Finally, the program can be asked to try to form subsets of the values of nominal test attributes.
| back to the top | |
![]()
With the fourth tab a decision or regression tree can be induced:
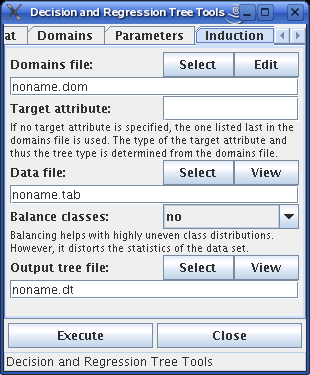
The induction of a decision or regression tree starts from a definition of attribute domains, which also yield the type of the target attribute and thus the type of the tree (decision tree for a nominal target attribute, regression tree for a numeric target attribute). For the domain file the file generated with the second tab may be used.
Next the name of the target field may be specified. If this input is left empty, the last attribute in the domain file is used, which, if the domain file was generated automatically, corresponds to the last field of a record in the data file.
In addition a data file is needed. If a decision tree is to be learned and the class frequencies are highly uneven in this data file, so that simply predicting the majority class leads to excellent error rates, it can pay to balance the class frequencies, which is done by modifying the record weights, so that all classes receive the same total weight. This can help the induction, but it should be kept in mind that such balancing distorts the data statistics.
The output decision tree, which is generated when the "execute" button is pressed with this tab in front, is written to the file specified at the bottom of the tab. It may be viewed by pressing the "View" button above the file name.
| back to the top | |
![]()
With the fifth tab an induced decision or regression tree can be pruned:
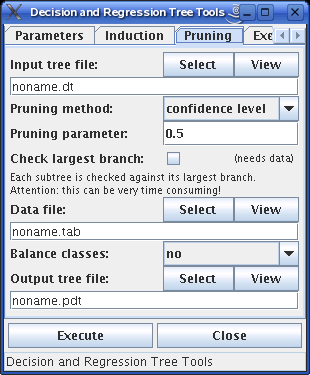
Pruning takes an input tree and writes an output tree. A data file may be used to prune the tree, but it may also be done without. If you do not want to use a data file, simply leave the corresponding input field empty.
There are three different pruning methods: none, which corresponds to reduced error pruning if a data file is used that is different from the one with which the tree was induced; pessimistic, which adds a user-specified fixed number of errors to each leaf, and confidence level, which uses the upper bound of a (formal, but not statistically valid) confidence interval for the leaf errors to determine the error rates. The pruning parameter is the number of errors to add to each leaf or the confidence level, respectively.
Furthermore, a maximum tree height may be specified (with 0 meaning that there is no limit) and it can be selected whether a replacement of a subtree with its largest branch (in terms of the number of training cases assigned to it, not in terms of the number of nodes) should be considered. This option requires a data file to take effect. In addition, it should be noted that on bigger trees it can be very time consuming and thus should be applied with care.
| back to the top | |
![]()
With the sixth tab a decision or regression tree can be executed on a data set:
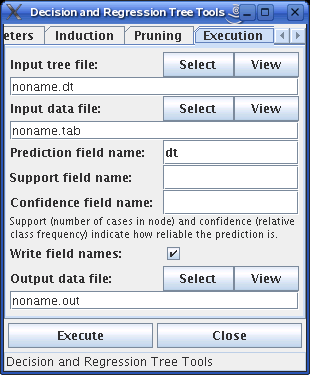
Here the decision tree to be executed and the input and output data files have to be specified. The name of the field to be added can be stated as well as names for optional fields containing the support (number of cases in the training data set on which the decision is based) as well as the confidence of the classification (percentage of correct predictions among those that are classified with the same leaf in the training data set). If the corresponding input fields are left empty, no such fields are generated.
By default the field names are written to the first record of the output file. If you do not want this, uncheck the corresponding box.
| back to the top | |
![]()
(MIT license, or more precisely Expat License; to be found in the file mit-license.txt in the directory regress/doc in the source package, see also opensource.org and wikipedia.org)
© 2004-2014 Christian Borgelt
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
| back to the top | |
![]()
Download page with most recent version.
| back to the top | |
![]()
| E-mail: |
christian.borgelt@softcomputing.es christian@borgelt.net | |
| Snail mail: Old |
Christian Borgelt Intelligent Data Analysis and Graphical Models Research Unit European Center for Soft Computing Edificio Cientifico-Tecnológico, 3a Planta c/ Gonzalo Gutiérrez Quirós s/n 33600 Mieres Asturias, Spain | |
| Phone: | +34 985 456545 | |
| Fax: | +34 985 456699 |
| Old E-mail: |
christian.borgelt@cs.uni-magdeburg.de borgelt@iws.cs.uni-magdeburg.de | |
| Old Snail mail: |
Christian Borgelt Working Group Neural Networks and Fuzzy Systems Department of Knowledge Processing and Language Engineering School of Computer Science Otto-von-Guericke-University of Magdeburg Universitätsplatz 2 D-39106 Magdeburg Germany | |
| Old Phone: | +49 391 67 12700 | |
| Old Fax: | +49 391 67 12018 | |
| Old Office: | 29.015 |
| back to the top | |
![]()